
In today’s data-reliant business environment, the importance of clean and accurate product data cannot be overstated. Unfortunately, many businesses continue to struggle with dirty product data, which can have significant negative impacts on their operations.
This article will explore the four most common issues surrounding dirty product data: duplicate data, poor language, missing data, and anomalies.
1. Duplicate Data
Duplicate data refers to the presence of identical or nearly identical entries within a dataset. This issue often stems from multiple data sources, manual data entry errors, or inconsistent data management practices. The consequences of duplicate data include:
– Spend Analysis Issues: Duplicate data skews financial analysis, leading to inaccurate spend assessments.
– Difficulty Locating Products in Warehousing: Redundant entries make it challenging to identify and track inventory efficiently.
– Decreased Data Reliability: When datasets contain duplicates, their reliability suffers, resulting in mistrust.
– Increased Costs: Duplicated orders or excess inventory can escalate operational costs unnecessarily.
– Reduction in Data Integrity: Data duplication undermines the integrity of the dataset as a whole.
– Operational Inefficiencies: Processes become slower and more complex, hampering productivity.
2. Poor Language
Poor language in data includes spelling errors, inconsistent terminology, and vague descriptions. These issues arise due to human error, lack of standardised terminology, or inadequate data governance. Poor language impacts businesses in several ways:
– Difficulty Locating Data: Inaccurate or inconsistent terminology makes data retrieval challenging.
– Issues Understanding Data: Misspellings and vague descriptions lead to miscommunication and misinterpretation.
– Operational Inefficiencies: Teams spend more time deciphering unclear data, reducing productivity.
– Integration Issues: Poorly labelled data hampers system integrations and interoperability.
– Decreased Trust and Credibility: Inaccurate language erodes confidence in the data’s quality and credibility.
3. Missing Data
Missing data refers to the absence of crucial product attributes or figures within datasets. This can occur due to incomplete data entry, poor data collection practices, or lack of standardised data requirements. The implications of missing data include:
– Poorer Understanding of Data: Incomplete datasets hinder comprehensive data analysis and decision-making.
– Location Issues: Missing location data causes difficulties in identifying where products are stored or shipped.
– Inefficiencies: Gaps in data lead to slower processes and hindered productivity.
– Inaccurate Spend Analysis: Missing cost data results in unreliable financial assessments.
– Reduced Growth: Incomplete datasets make it challenging to identify growth opportunities.
– Reduced Trust: Gaps in data undermine stakeholder confidence in its reliability.
4. Anomalies
Anomalies in product data are unexpected values or formats that deviate from the standard, such as incorrect units (e.g., millimetres instead of inches) or measurement systems (e.g., Celsius instead of Fahrenheit). Anomalies typically arise due to human error, inconsistent data standards, or system integration issues. The effects of data anomalies include:
– Reduced Trust in Data: Inaccurate values erode confidence in the dataset’s integrity.
– Downtime in MRO Operations: Misleading values cause delays in maintenance, repair, and operations.
– Legal Issues: Incorrect data can lead to compliance violations and legal consequences.
– Reduced Safety: Anomalies in safety-critical data may lead to hazardous situations.
– Reduced Growth: Data inconsistencies hamper the identification of market trends and opportunities.
– Inefficient Resource Allocation: Erroneous data leads to misallocation of resources.
– Compromised Data Analysis: Anomalies distort analytical models, leading to incorrect insights.
– False Alarms: Misleading values trigger unnecessary alerts and actions.
– Errors in Decision-Making: Decisions based on inaccurate data can result in costly mistakes.
– Reduced Predictive Accuracy: Anomalies degrade the accuracy of predictive models.
How AICA Helps
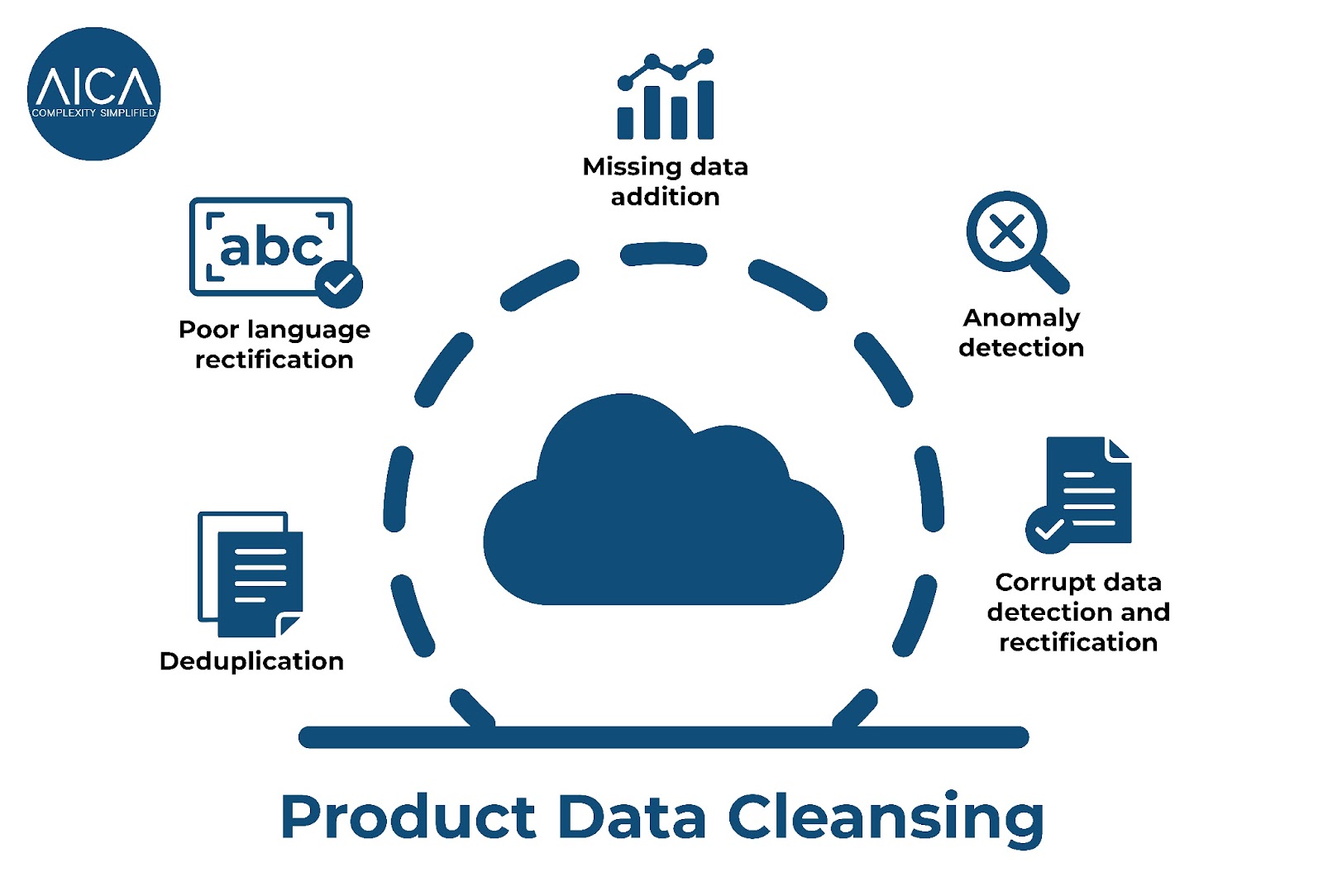
AICA helps organisations in automating the process of product data cleansing, addressing the issues outlined above. Our narrowly focused AI and ML algorithms, trained specifically on MRO data, help detect and guide users in correcting these issues. By automating product data cleansing, we:
– Detect Duplicates: Identify and flag duplicate entries for user review, helping reduce data redundancy.
– Improve Language Quality: Highlight spelling errors and standardise terminology, ensuring consistent data language.
– Fill in Missing Data: Use predictive analytics to suggest missing attributes, improving data completeness.
– Resolve Anomalies: Detect and correct anomalies in measurement units, formats, and more.
Through these efforts, AICA helps organisations save time, reduce costs, and improve data integrity by providing cleaner, more reliable product data.
To Conclude
Dirty product data can significantly impair business operations, leading to increased costs, operational inefficiencies, and a reduction in data integrity. By understanding the most common issues, such as duplicate data, poor language, missing data, and anomalies, businesses can better address and mitigate these challenges.
Ready to cleanse your product data and unlock its full potential?
Visit our website today to learn more and become a partner today!
Copyright Reserved © AICA Data International Ltd 2024